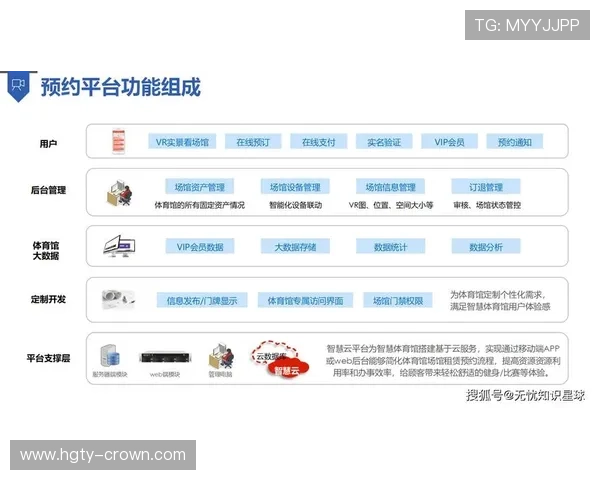
文章摘要:本文以“基于欧冠大数据的保姆级风险控制分析与实战指南方法论全流程解析”为核心主题,系统梳理从数据获取、模型构建、风险识别到实战落地的完整逻辑链条。文章首先从宏观视角概括欧冠赛事大数据在风险控制中的价值与意义,强调数据驱动决策在复杂不确定环境中的核心作用。随后,围绕数据基础建设、风险评估模型、动态控制机制以及实战应用转化四个方面展开深入解析,力求以通俗但不失专业的方式,拆解“保姆级”方法论背后的思维框架与操作路径。通过多维度、多层次的论述,帮助读者理解如何在欧冠这样高强度、高关注度的赛事场景中,建立可复制、可迭代、可验证的风险控制体系。全文既注重理论完整性,也强调实战可行性,旨在为希望借助欧冠大数据进行科学分析与稳健决策的读者,提供一套清晰、系统且具有落地价值的参考指南。
皇冠体育博彩在进行任何风险控制分析之前,数据基础的构建都是第一步。欧冠赛事本身具有赛程密集、球队背景复杂、变量众多等特点,这决定了数据来源必须全面而系统。常见的数据包括球队历史战绩、球员个人表现、伤停信息、赛程密度以及主客场因素等,这些信息构成了最原始的数据底座。
在数据收集阶段,尤其需要注意数据的时效性与一致性。欧冠赛事跨度长、阶段多,不同阶段球队状态差异明显,如果不对数据进行时间切片和标准化处理,很容易在后续分析中引入偏差。因此,建立统一的数据口径和更新机制,是保证分析结果可靠性的关键前提。
此外,数据清洗与特征工程同样不可忽视。原始数据往往存在缺失、噪声或重复问题,需要通过规则校验、异常检测等方式进行处理。通过对关键指标进行重新组合与抽象,可以将零散的数据转化为更具解释力的特征,为后续风险识别与模型分析打下坚实基础。
在完成数据基础建设后,风险评估模型的设计成为核心环节。所谓风险,并非单一结果的好坏,而是结果不确定性与波动性的综合体现。因此,模型设计需要从概率分布、波动区间和极端情况等多个维度进行考量。
常见的做法是结合统计模型与机器学习方法,对欧冠比赛结果及关键事件进行建模。统计模型能够提供清晰的因果解释,而机器学习模型则更擅长捕捉非线性关系。二者结合,有助于在可解释性与预测能力之间取得平衡。
值得强调的是,风险评估模型并非一劳永逸。随着赛事推进、样本结构变化,模型参数和权重需要动态调整。通过回测与交叉验证,可以不断检验模型在不同阶段的稳定性,从而避免在实战中因模型失效而放大风险。
有了风险评估模型,并不意味着风险已经被完全控制。欧冠赛事中,临场因素往往会对结果产生巨大影响,例如突发伤病、战术调整或外部环境变化。因此,动态风险控制机制显得尤为重要。
动态控制的核心在于实时监测与快速响应。通过持续跟踪关键指标的变化,可以及时识别风险信号。当指标偏离正常区间时,应触发相应的预警机制,为决策者提供调整空间,而不是被动接受结果。
同时,动态风险控制还需要明确边界条件和止损逻辑。无论模型多么精细,都无法消除所有不确定性。通过事先设定可接受的风险范围,并在超出范围时果断采取措施,可以有效避免风险的累积和放大。
方法论的最终价值,体现在实战应用中。在欧冠大数据风险控制的实战阶段,关键在于将分析结果转化为可执行的决策建议。这一过程需要兼顾模型结论与现实判断,避免机械套用。
在实战中,应通过小规模验证逐步放大应用范围。先在有限场景中测试方法论的有效性,观察风险控制效果,再根据反馈进行优化。这种渐进式落地方式,有助于降低试错成本,提高整体稳定性。
最后,实战应用必须形成闭环迭代。通过对每一阶段结果的复盘,总结成功与失败的原因,将经验反哺到数据与模型中。长期来看,这种持续迭代的机制,才能让基于欧冠大数据的风险控制体系不断进化。
总结:
综合来看,基于欧冠大数据的保姆级风险控制分析,并不是单一工具或技巧的堆砌,而是一套贯穿数据、模型、机制与实战的系统方法论。从数据基础构建到风险评估,再到动态控制与实战迭代,每一个环节都相互关联、缺一不可。
通过全流程视角进行思考,可以帮助我们在复杂多变的欧冠赛事环境中,建立更加理性、稳健的分析与决策框架。这种以数据为核心、以风险为导向的方法论,不仅适用于欧冠场景,也为其他高不确定性领域提供了有价值的参考思路。